Why LabVIEW Slower with 3D Array Diagonal Iteration (Compared to Rust)
When iterating diagonals of a 3D array, the performance differences between LabVIEW and Rust become very noticeable. Even with a straightforward implementation, the generated machine code tells a story about what’s happening under the hood.
If we compare LabVIEW-generated machine code side by side with equivalent Rust code (even a non-optimal implementation like a triple Vec<Vec<Vec
Screenshot from NI Forum Post:
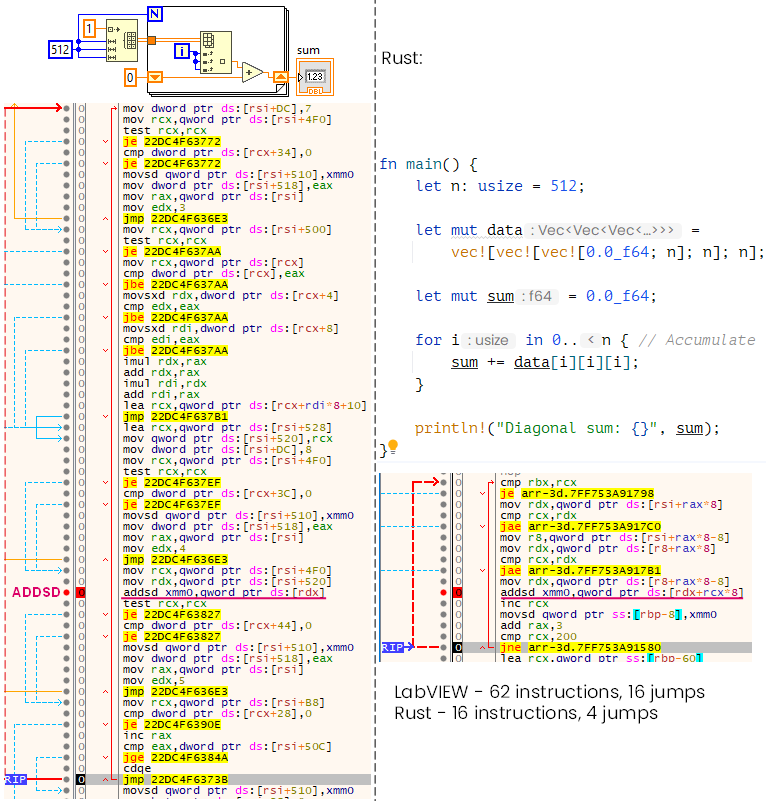
This overhead dominates the actual computation, especially in tight nested loops such as diagonal traversal.